

Mitochondria is the powerhouse of the cell. We've all heard it and we all know how to say it. However, few actually know what it means beyond the words. Same goes for "a thread is a lightweight process".
As you would have guessed, the primary motivation for writing this post stems from my dislike of throwing words around without conveying anything meaningful, which is in abundance in current times. Anyway, let's get to the point. This post is an attempt to dive deeper (limited by my reasoning skills) into "threading" behaviour in**Linux, mainly for my own information, hence the language might come off as more on a conversational side with myself.
Also, given how separate OS have represented these concepts differently and the way this information is mangled together and taught at college level, it gets quite confusing. Just try searching for threads vs processes and you will come across 20 different threads (no pun intended) with 20 different answers :)
Preface
A long long time ago, actually 15 years (I was in school), I first came across the obnoxious term, a thread. A process still made sense to me to be visualized as a container executing my favourite program/code (Dota 1 at that point) and holding some data. However, I was left pondering that what the hell is a thread? To me it seemed like a physical entity (like an actual thread, yes) lying deep within the realms of CPU and can't be seen meanwhile doing some magic.
Fast forward -> You realize details are generally dumbed down at application usage level and most things are an abstraction to make life "simple". So, what are we looking at?
It's a process.. It's a thread.. It's Superman
Well, technically it's none. In Linux, the basic unit of execution is a task which is represented by a task_struct data structure. It is the only thing that exists at the lowest level and concepts such as a process and thread are representations on top of it.
This can be reasoned around 2 facts -
Multi-processor systems were not a common thing back then. There would be work being done on it for UNIX-like & Windows systems, but that would be primarily in the proprietary domain. No standardized open-source OS existed to build around the concepts of multi processing/threading.
Hardware and software massively evolved since the initial kernel version, which would have been primarily designed for a single CPU machine.
With advancements in both breadth (available OS choices) and depth (multi-processing systems) it would have become important to formalize the tools via which you can build and run efficient multi-processing applications safely, reliably, and with deterministic performance.
Enter Sandman POSIX
History
Pre 2.6
Post 2.6 - POSIX contracts
fork() -> Used to create a new process. This actually creates a copy of the current process as in a Linux system no process is independent of any other process. Every process in the system, except the initial process has a parent process. New processes are not created, they are copied, or rather cloned from previous processes. The parent and the child are completely independent, each with its own address space, with its own copies of its variables, which are completely independent of the same variables in the other process. Once a copy is created it can go ahead and execute it's own code.
pthread_create() -> Used to create a thread.
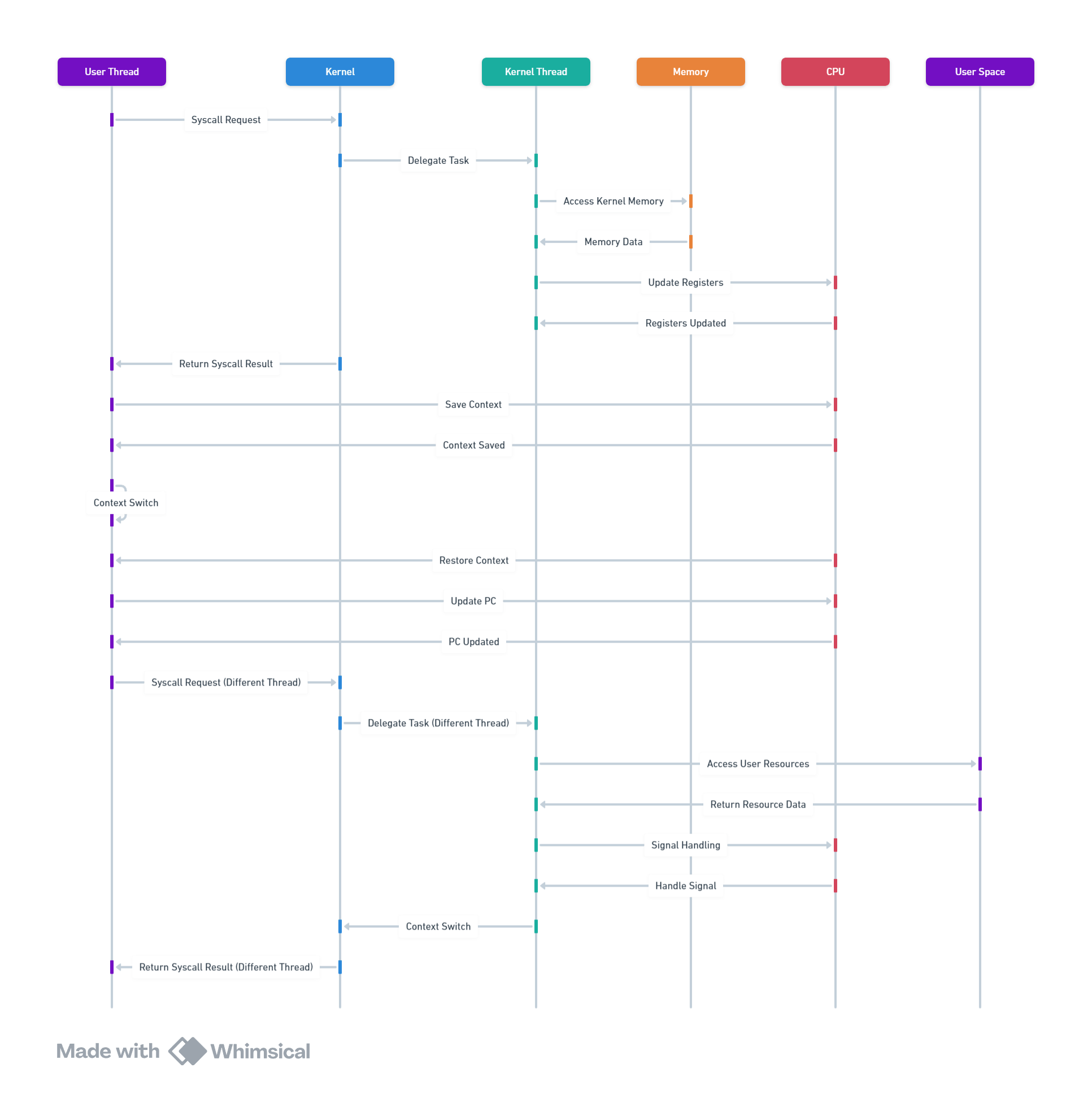
However, internally there's only system call in Linux called clone() which takes various parameters to schedule a task and fork() and pthread_create() delegate the job to clone() by passing the required params and is the only distinction between the two. The main idea here is to pass params corresponding to sharing memory, network/system resources, file descriptors etc. while creating a thread (there will be other params which instruct the thread to have it's own resources like stack, program counter, local variables) but not during creating a process as they need to be isolated.
Things don't end here
If you noticed I had to introduce a term called user space in the above section. On the contrary there's kernel space as well.
kernel space -> This is the area where the Kernel is supposed to allocate and manage it's resources and perform it's job i.e. scheduling processes, managing memory, handling input/output operations, and providing an interface for user space processes to interact with hardware.
user space -> This is the area used to run user-level processes (applications) and manage the direct resources used against them.
Why do they exist?
The single most important job of the kernel is to ensure that the OS functions in a safe, reliable, efficient, and performant manner. It can only do so with having full control of the execution environment and enforcing guardrails around interference. This is essentially the kernel space boundary. Applications can be managed in a dedicated user space and any system resource usage have to be requested via the kernel.
Threads distinction
Ultimately a physical entity is tasked to execute instructions i.e. the CPU core which can run 1 thread at a time. It can have logical cores (some scheduling program) that can again run a thread itself (It is likely achieved via hyperthreading which Intel processors claim to be hardware magic). The idea is to maximize the utilization of the core as a single thread might still get blocked on accessing a system resource and the core can be used for computation for the idle thread.
Kernel threads -> These are the actual threads which can be executed on the processor, managed by the kernel scheduler. These are also termed as OS threads and given the representation of being comparatively heavier to user/green threads because they have to deal with the kernel, and other aspects such as priorities, permissions. The kernel will also use them to execute it's instructions apart from executing application/user-process related tasks.
User/Green threads -> User threads are a runtime abstraction (they are not "real" - Joi from Blade Runner 2049) i.e. it's completely managed by the application/user-process (ex - Goroutines and Kotlin coroutines). This also means, the runtime also simulates a scheduler and context-switching capabilities. However, as it's outside of the kernel, the responsibilities are quite minimal and thus the resource allocation requirements as well, hence the representation of being comparatively lighter than kernel threads. Also, they will always exist within the same process hence accessing memory (used by the process) and context switching will also be faster.
Mapping models
1:1 - Simplest, maps one user thread to a kernel thread. In Linux the user thread represented by the call to pthread_create() is always mapped to 1 kernel thread.
1:N - Maps multiple user threads to a single kernel thread. Hardly used anymore, If a particular user threads blocks the kernel thread the entire process blocks.
M:N - Maps multiple user threads to a smaller number of kernel threads. Theoretically better than both of the above but very hard to implement. Goroutine scheduler simulates this mapping.
What does this mean?
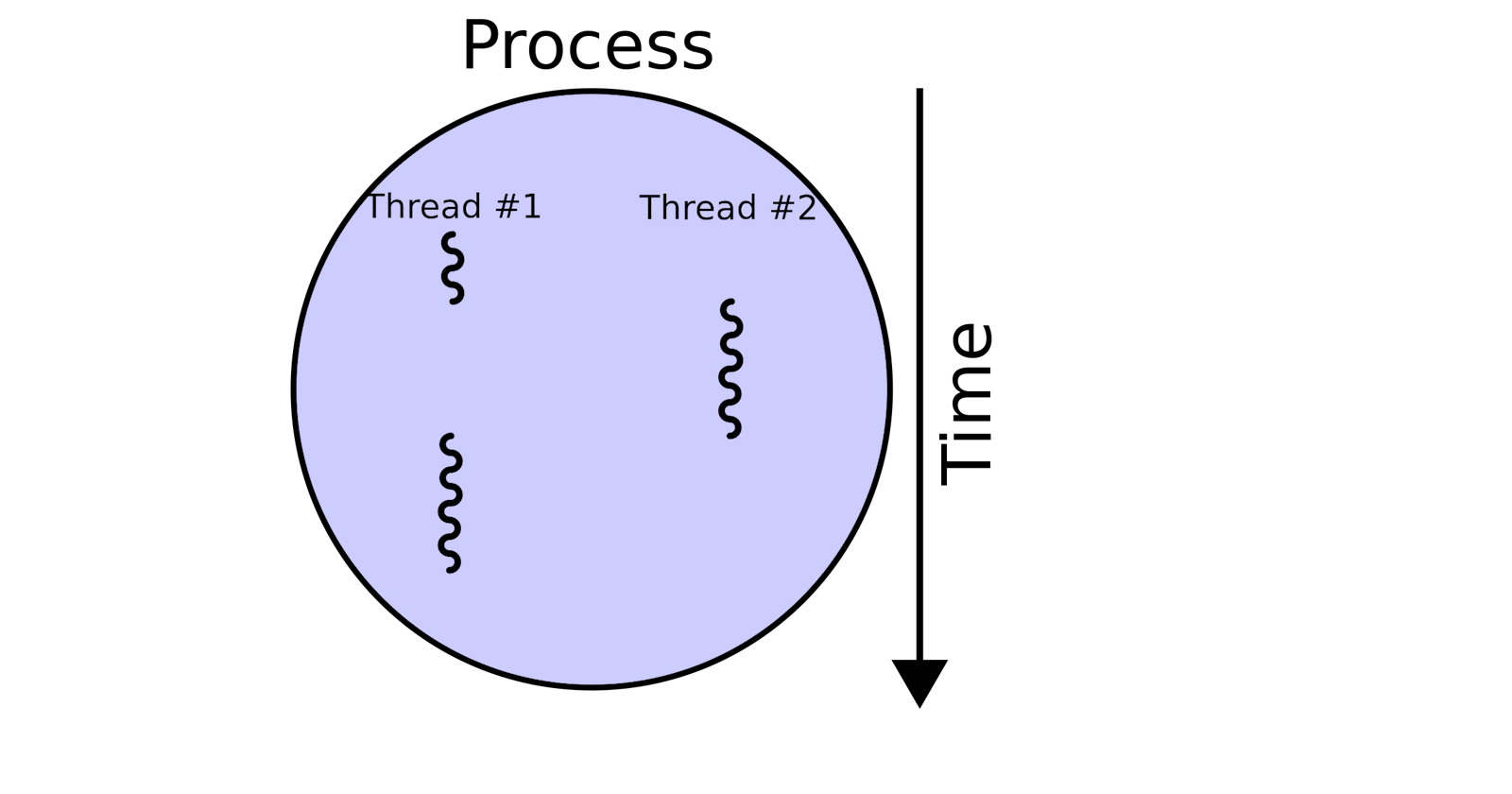
Any user thread needs to delegate the actual task to a kernel thread via a syscall in order to utilize the processor for any sort of computation. They cannot run on their own. Below can be a visual representation of it -
Summarization
Process - A process is just a program in execution i.e. code + required resources to run it, which can be memory, file descriptors, program counter, etc. Processes are meant for strong isolation against other processes running on the OS.
Thread - Thread is just a sequence of instruction to be executed. You can also visualize a process as a collection of threads. They share common resources within a process except maintaining it's own stack, counters and variables. The upside being less resources to be allocated for creation and easier context switching and the downside being synchronization around shared state and data within the process. Ultimately, a thread is going to get executed on the CPU core which is managed by the underlying kernel.
Bonus
Why is it generally said that if the workload is I/O bound you can spin up multiple threads for parallel processing but you shouldn't if it's CPU bound? Doesn't the I/O activity utilize CPU in any aspect?
This is a great answer which puts "there's no free lunch" into perspective - https://stackoverflow.com/a/13600633
Although this might seem like a lot of stuff, I am still unsure about quite a few things having researched about it on the web. Seemingly, there lacks a good way to linearly track the essential architecture updates in a system over a time frame of 20-30 years. There are a lot of different answers to the same question in different contexts and it just leads to information getting mangled and causing more confusion than clarity!